A Simple CNN Classifier for Domain Name Industrial Market Segmentation
The Problem
Many analytical and technical tasks in today’s world can employ a classifier: a good classifier generalizes patterns and uncovers important hidden features in a data set. Over the years, as we’ve been focusing on providing engaging user experiences for small business owners, developing a good classifier that can accurately determine a domain name’s industrial market segmentation is in high demand. Since we have a large amount of users on-board from GoDaddy Website Builder, we are finally in a good place to solve this problem by leveraging neural network technologies.
A Closer Look
Text classification is a common practice in the industry. For more information on text classification, this article written by Mirończuk & Protasiewicz gives an awesome review of the recent state-of-the-art elements of text classification.
In most real-life applications, if the classifier is performed on a larger set of labels, it always helps the model to predict better if a longer text is given. The requirements for our task though is a little different. Do we have a long text input to run the classifier on? Absolutely not, a domain name on average has only 3-5 words – that’s even shorter than most sentences. Do we want to cover as many categories as possible? Yes! The whole point is to get a comprehensive view of domain industrial market segmentation. I hope you are with me now, this task is challenging and ambitious.
The domain name dataset presents a number of other challenges; here are the the problems we dealt with when building this model:
Problems
- Problem 1: How many categories should we keep in the model, given the difficulty in predicting multiple categories from very short text lengths?
- Problem 2: How to deal with noise in the data?
- Problem 3: Can we improve the model by adding network layers or increasing the embedding size?
- Problem 4: Should we embed the input domain at word level or character level?
The Model
To tackle the problem of classifying domain names to an industry category, we implemented a classic Convolutional Neural Network (CNN) classifier (learn more here at Google CNN Tutorial and Stanford CNN Tutorial). To generalize the model at a very high level, it takes input as a string in the form of words contained in the second-level domain (SLD) – for example: "www.iamanexample.com" –> "i am an example", projects it into vector space by using a word embedding. Then the CNN cells of various sizes start sliding over the vector space text, to collect features in different flavors. A max pooling layer follows to get the feature mappings. Then all the locality information in the feature mappings merge through a fully connected layer for optimizing over softmax. Finally, the category predictions will be obtained from there. Please check out these excellent explanations on how a CNN and Max Pooling works: CNN explained on Quora and Max Pooling explained on Quora.
Dropping Weights From A Machine Learning Model – Less is More
Now, let’s talk about Problem 1. One important thing I learned from doing this project is we have to be realistic about technology. Sure, deep neural networks are awesome, but they are not magic. Intuitively, a deeper and more complicated network structure would be more intelligent and able to handle more profound logic. However, if the problem itself does not always have a black and white answer, there will be a cap on how well the model can perform. For example, if some newly discovered alien language is presented to you and the model, neither you nor the model would be able to decipher it, since none of you have any prior knowledge about it. Similarly, if you see just the word “apple” without any context, you’d be confused whether it refers to the tech company or the fruit, and the model will think alike. So, the answer is, we can’t keep every single category. The categories shouldn’t be very specific either, as there is only so much we can infer from a very short text.
-
The 80/20 Rule
GoDaddy Website Builder is supported by a collection of over 1,600 categories, which is designed to encompass every existing business type. Yet, businesses with an online presence are distributed with a long-tailed nature – highly skewed at categories like “Photography”, “Real Estate”, “Fashion”, etc; but few in categories like “Pet Fashion”, “Lighthouse”, etc. Therefore, we can cut down the amount of categories by over 50% but lose only 10% of businesses, since so few businesses are represented in the long tail of categories. This helps us largely simplify the problem with a minimal performance loss.
-
More Accurate at A Lower Resolution
The categories in this collection are organized in a hierarchical structure that are often not mutually exclusive. For example, “Himalayan or Nepalese Restaurant” is a subcategory of “Restaurant”. Conceivably, we could create millions of features, add additional layers and complexities in the model, to make it perform across all these categories. However, the goal is to teach the model human intuition. Not to mention a more profound model usually requires a much larger data set, takes more time and resources to train and performs much slower. Therefore, we decided to only look at the very top level of the hierarchical structure, and reorganize it to keep the top levels mutually exclusive with each other.
The reorganized category set is what’s finally used for training the model, we will call it the “model label set” in the rest of the article. The raw data will be relabeled according to the “model label set” , and it will be called “relabeled data”.
The Data
Woohoo, it comes with the label!
Moving on to Problem 2. Before I dive into the noisiness of the data, I want to first emphasize the convenience in obtaining a curated data set. A supervised classification problem requires a well labeled data set. In many real-world practices, this means heavy manual labeling work needs to be done by a group of trained annotators. It is usually time consuming and expensive. Luckily with GoDaddy Website Builder, a newly acquired customer will potentially contribute to the date set by providing a category label that best describes their own site. Therefore we are able to associate a piece of short text such as site name, domain name, site description and title, etc, with the self-report category label. It is such a beautiful convenience that saves us tremendous amount of time and effort in data labeling.
But wait a second…
However, just like any self-reported data, the quality can be a concern. On top of that, unlike other self-reported data, the question we are trying to collect an answer for is very difficult – as I mentioned earlier, the category collection has a very complicated hierarchical structure with over 1,600 choices in total. As you may imagine, a majority of people left their answers empty, or prematurely answered, without thinking through, in order to proceed to the next steps. Even when the answers were carefully filled out, inconsistencies are very likely to occur.
Because of this we needed to massage the raw data to generate a higher quality relabeled data set to train the model on. The “relabeled data” can be obtained by repeating Cleaning and Relabeling steps iteratively, until it is converges to a stable stage. The set of categories covered by the relabeled data is the “model label set”. (see Figure below)
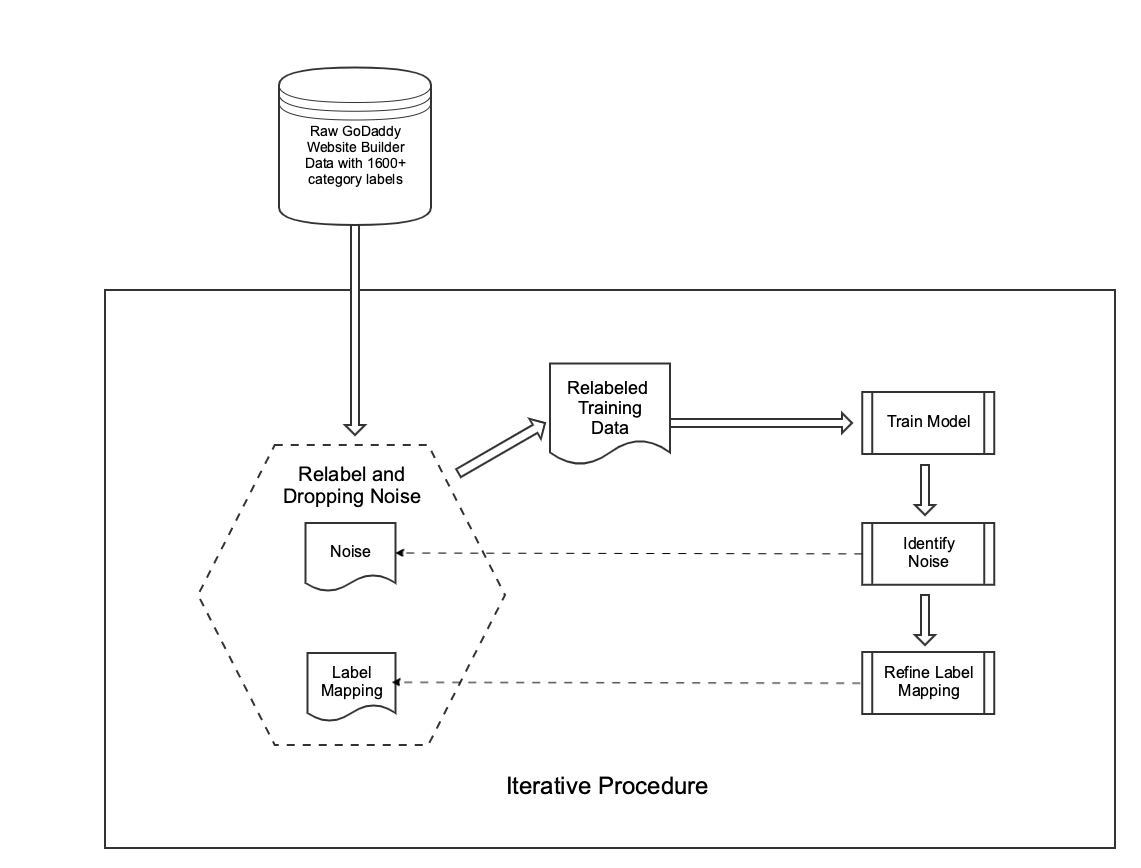
-
Cleaning - Bad Data
A model learns patterns in the data. If the data itself is of low quality, the model will pick up poor knowledge and perform badly. Therefore, using techniques to identify and remove invalid or low quality data from the training set is very crucial to obtaining an optimal model. We consider a training example as valid when the short text consists of at least one English dictionary word, as well as when the original category label could be mapped to a label from the “model label set”.
-
Relabeling - Good Data with Disagreements
Individuals can behave inconsistently: we observed this in so many examples where people use the same name for different industry categories; or choose different industry categories when the business names essentially describe the same thing. Relabeling the data completely manually is very tedious and error-prone and thus can easily introduce even more noise. Therefore, we chose to use the previous model to help assist the relabeling process. After we obtained a model from the last iteration, we will examine this model’s prediction accuracies category by category, review wrong predictions with high confidence levels (see code below). This will allow us to quickly identify dominating mislabel trends in the previous relabeled data, so we can then correct and adjust to form a new set of relabeled data and model label set for the next iteration.
# Accuracy by Categories
with tf.name_scope("category_acc"):
accs = []
true_vals = tf.argmax(self.input_y, 1)
correct_predictions = tf.nn.in_top_k(self.scores, true_vals, topn)
for c in range(self.input_y.get_shape()[1]):
c_val = tf.constant(c, dtype=tf.int64)
where = tf.equal(true_vals, c_val)
c_correct_predictions = tf.gather(correct_predictions, tf.where(where))
accs.append(tf.reduce_mean(tf.cast(c_correct_predictions, "float")))
self.category_accs = tf.stack(accs, name="category_acc")
# Top Misclassified
with tf.name_scope("misclassified_conf"):
top_confs = tf.reduce_max(self.scores, reduction_indices=[1])
true_vals = tf.argmax(self.input_y, 1)
correct_predictions = tf.nn.in_top_k(self.scores, true_vals, topn)
if_wrong = tf.cast(tf.equal(tf.cast(correct_predictions,dtype=tf.int32), tf.constant(0)),dtype=tf.float32)
self.wrong_confs = tf.multiply(top_confs, if_wrong, name="wrong_confs")
After applying the above methods, the final training data set contains around 127,000 unique valid training examples, covering 26 category labels in total, listed below. Perhaps the size of the data appears to be disappointing for you Machine Learning enthusiasts, but it really is a “quality over quantity” choice. Furthermore, this data was obtained from 2 years ago, and we are at a much better place to stretch its ability to perform on a more complex model from a much bigger data corpus.
Currently Supported Model Labels
- Active Life
- Arts & Entertainment
- Automotive & Vehicles
- Child Care
- Cosmetics & Beauty Services
- Education
- Event Planning Services
- Fashion
- Financial Services / Organizations
- Fitness & Gyms
- Food & Drink
- Furniture & Home Decor
- General Consulting
- General Shopping & Retail
- Home Contractors
- Lawyer & Attorney
- Local Services
- Massage & Spa
- Medical & Hospital
- Other Home Services
- Pets
- Photography Services
- Public Relation & Branding Services
- Real Estate
- Technology
- Travel & Vacation
Model Selection
I’m going to address Problem 3 and Problem 4 together in this session. In order to develop a method efficiently, we did not get a chance to look into character level embedding or trying out different network structures. However, we did experiment with different combinations of model parameters including embedding dimension, number of filters and filter sizes (See table below to find out different values we tried). The model evaluation and selection is done while doing iterations of data cleaning and relabeling, on a set of benchmark data. This benchmark data is randomly sampled and carefully reviewed, so it represents the data distribution and has the ideal category label associated.
| Model Parameter | Values to Choose |
|---|---|
| Embedding Dimension | 64; 128 |
| Number of Filters | 32; 64 |
| Filter Sizes | 3,4,5 |
As mentioned earlier, the size of the training data is pretty small, we found without surprise the model performs considerably better when the network is simple and involves less training parameters. The final model we chose to use performs with an accuracy of 89%, on the benchmark data set: this value had passed our acceptance criteria and thus we did not explore other optimization strategies. The parameters used are the following:
- Embedding Dimension = 64
- Number of Filters = 64
- Filter Size = 3,4,5
Here are a few examples from the model:
cheesecakefactory.com --> Food & Drink
catlovers.com --> Pets
travellight.net --> Travel & Vacation
getfitwithraina.net --> Fitness & Gyms
helpwithlaw.org --> Lawyer & Attorney
This Domain Classifier is currently giving support to multiple teams within GoDaddy. For example, business intelligence team uses domain name industry category information to segment users and identify more industry-sensitive needs and potentials; domain name search team uses name industry category information to give industry related recommendations to improve user experiences.
Conclusions
This article details our experiences in developing and deploying a powerful model that can classify a domain name into an industry category. I hope it would be helpful for those considering a related problem. As there are so many great examples online regarding CNN classifiers for all different kinds of interesting problems, my goal here is to share my experience on how to identify the unique challenges for a specific real-life problem and how to solve them efficiently using the limited resources available. Please don’t hesitate to reach out to me on LinkedIn. Your thoughts, contributions and questions are always welcome!
Acknowledgements
Wenbo Wang contributed to the development of the model, Navraj Pannu provided valuable feedback on this blog post.
