GoDaddy Studio’s Journey with State Management and MVI / Unidirectional Data Flow on Android
History ⌛️
The GoDaddy Studio Android app began with a fresh codebase around the end of 2018. This was around the same time Kotlin was starting to become a popular choice and the community had moved on from choosing MVP as the preferred architecture choice, to MVVM. We decided to adopt MVVM where it made sense, but we were intrigued by the prospects of MVI/Unidirectional data flow. After watching a few presentations on the topic, we proceeded to design our Canvas Editor screen using a homegrown version of MVI, very similar to the code described in this presentation.
As time went on, we started facing issues with the MVI approach. The way we implemented it, unfortunately, allowed for race conditions and caused a lot of headaches for the team. It was at this point that we decided to investigate using existing frameworks for unidirectional data flow and see if they could solve the problems we were seeing. After evaluating a few, we settled on using the Spotify Mobius Framework for various reasons which we will dive into in this blog post.
State Management
Let’s step back a bit and learn about the issues we faced with our approaches over the past couple of years. What does it mean when we talk about State Management for UI? State management refers to keeping track of how a user interface should look and how it should react to different user inputs. On a complex screen with plenty of buttons, gestures and text input - managing the state is a full-time concern.
Take this screen for example:

There are plenty of concerns that need to be managed and tracked on this screen alone:
- What should happen when the project is loading up?
- Has an error occurred?
- What is the currently selected tool on screen?
- What are the layers and properties that should be displayed in this project?
Not only is there the current state of what should be rendered on screen, but there are many different interactions that need to mutate this state - scaling gestures, button taps, colour changes, etc.
MVVM and the issues we faced 😣
A couple of years ago, the Android community began advocating for using some kind of architecture, as we all realized that placing all your logic inside the Activity, was a perfect recipe for the messiest spaghetti bolognaise you could imagine (delicious but not very elegant).
First came MVP (Model-View-Presenter) and there were great benefits to applying this architecture to our apps: we got testability, separation of concerns and the ability to re-use logic on other screens.
Then came along MVVM (Model-View-ViewModel), which solved a lot of issues that MVP had: mostly the ability to have the ViewModel unaware of the View or who was listening to any changes that are happening.
We were using MVVM in certain places in our app, but we very quickly found issues with how we approached using MVVM.
Let’s take a look at this example of how we were using MVVM, and the issues we faced with it.
MVVM ViewModel example
This is the typical ViewModel that we would set up in the App: With multiple LiveData fields, all exposing different bits of the UI state:
class ProjectEditViewModel: ViewModel() {
val isLoading = MutableLiveData<Boolean>()
val project = MutableLiveData<Project>()
val error = MutableLiveData<Throwable?>()
fun createProject() {
isLoading.value = true
repository.createProject()
.subscribe( { project ->
isLoading.value = false
project.value = project
}, { error ->
isLoading.value = false
error.value = error
})
}
}
This example looks good - loading and setting a project. But think of this scenario: a user clicks on the “create project” button, and it fails, populating the “error” LiveData. They click “create project” again and it succeeds but the error value is still populated. Now we have a loaded project and an error screen shown at the same time, what is the correct state to show to a user?
Some might solve this problem by saying: “You need to reset the error.value inside onSuccess“ and whilst that could help improve things, the very nature of these LiveData observables being separate objects, is the bigger issue here. Let’s go a bit deeper into why multiple observables can be problematic.
This is how we would typically observe these LiveData objects for changes inside the Fragment:
class ProjectFragment: Fragment() {
fun observeViewModel() {
viewModel.isLoading.observe(this, {
// show loading or hide it
})
viewModel.project.observe(this, {
// show project
})
viewModel.error.observe(this, {
// show error or hide it
})
}
}
From this example, it is difficult to know what the UI of the screen will look like at any point because each LiveData observable can emit a new state at any point in time. If we start adding new functions to our ViewModel that emit new loading or error states, would you be able to describe what the UI will look like at a single point in time?
This can result in a race condition since these separate observables can emit state changes independently. What would the state look like if an error is emitted but there is currently a project loaded?
Typically these kinds of issues manifest on the UI with overlapping states like in this example we had from the app:
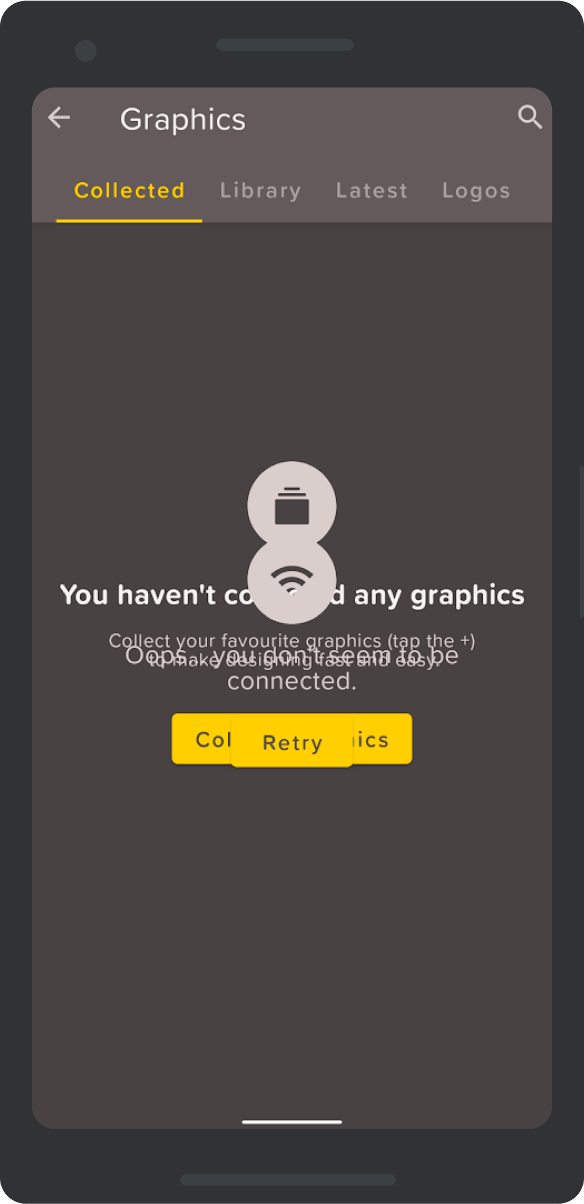
There are several drawbacks when using this approach of MVVM with separate LiveData objects:
- It is hard to know at a single point in time, what the UI should look like if there are multiple LiveData objects that change the state of the screen.
- There is no single snapshot to be able to recreate the UI from easily.
- This also then begs the question, are we handling all the potential cases here?
One way to potentially improve on this behaviour, is to use data classes that contain the state information in one class and expose only a singular LiveData object to the UI. This would help solve the issue of having multiple observables emitting different state that we’d need to keep track of, and it’s a building block of how MVI can work, as we will explore next.
MVI / Unidirectional Data Flow
Now that we understand where potential issues can come from with MVVM and multiple LiveData observables, let’s talk a bit about Unidirectional Data Flow and MVI (Model-View-Intent) and our experience with them.
With Unidirectional Data Flow everything is modelled around a single state object. This state is immutable, to prevent unwanted side effects. There is a clear flow of how data changes through the system, since it only happens in a single direction.
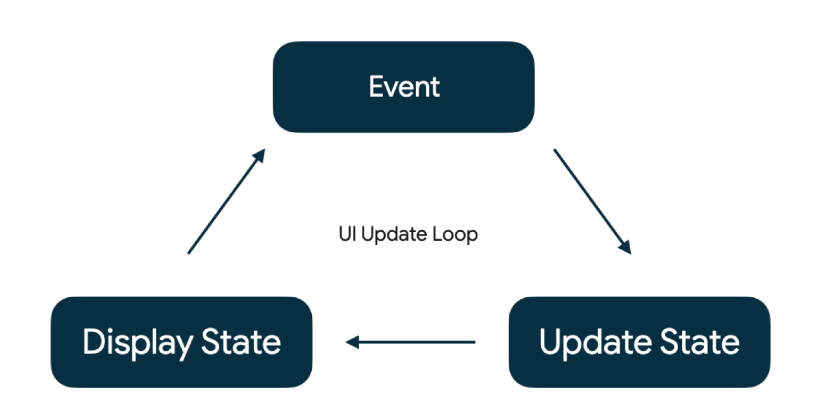
A user performs an event (or action/intent as used in other examples of MVI), for instance, they open a screen that calls LoadProjectEvent, the event is processed to produce a new state and that state is rendered on screen.
With this flow of data, you can easily reconstruct your screen from a single model update without needing implicit state set from other observables.
Our homegrown MVI framework
As mentioned at the start of this post, we took inspiration for our MVI implementation from this example online. In the diagram below, you can see that the flow of data is in a single direction. We have a View that emits “Actions”. The ViewModel then takes the Action and sends them to the Processors which perform operations asynchronously to deliver a Result to the Reducers. Reducers take the Results and the current State of the screen and produce a new State which the View then renders on-screen.
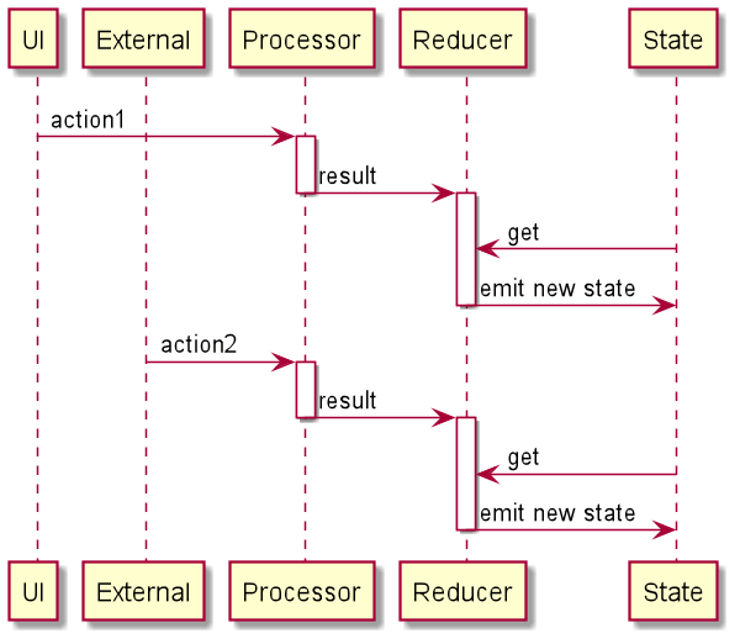
With this mechanism in mind, the code looked as follows. The EditorAction ‘s were fired from the UI, and the EditorState is an example of what the single state of the UI could look like:
sealed class EditorAction {
data class LoadProjectAction(val identifier: String): EditorAction()
data class AddLayerAction(val stuff: String) : EditorAction()
// more actions here...
}
data class EditorModel(
val project: Project? = null,
val activeFocusTool: LayerTool? = LayerTool.NUDGE,
val loading: Boolean = true,
val error: Throwable? = null)
To load up a project in the background, we would have these observables (that all can run concurrently), and they would produce Results once the background execution has finished:
val projectLoadProcessor = ObservableTransformer<ProjectAction.LoadAction,ProjectResult.LoadResult> { actions ->
actions.flatMap { action ->
projectRepository.loadProject(action.projectId)
.map { project ->
ProjectResult.LoadResult.Success(project)
}
.subscribeOn(Schedulers.io())
.startWith(ProjectResult.LoadResult.InFlight)
.onErrorReturn(ProjectResult.LoadResult::Failure)
}
}
It is worth mentioning that in the code above: we were also doing some bad things*, we were storing a state in memory in the ProjectRepository and mutating that in-memory project from all these different observables! (More on this later)
The reducers then took these Results produced by the processors, combined with the current state, and produced a new state for the UI to display:
class ProjectResultReducer : Reducer {
override fun reduce(state: EditorState, result: EditorResult): EditorState {
return when (result) {
is ProjectResult.LoadResult.Success -> {
state.copy(
project = result.project,
)
}
is ProjectResult.LoadResult.Failure -> {
state.copy(
error = result.error
)
}
}
}
}
This is a snippet from what the EditorViewModel used to look like, using RxJava PublishRelay to combine all the Action Processors and Reducers to produce a new state:
class EditorViewModel : ViewModel() {
private val actionsPublisher = PublishRelay.create<EditorAction>().toSerialized()
val state = MutableLiveData<EditorState>()
init {
actionsPublisher
.compose(actionProcessors) // compose multiple observables together concurrently
.scan(EditorState(), resultReducers) // setup initial state & reduce
.subscribe({
state.value = it // update LiveData state after reducer emits new state
}, Timber::e)
}
fun onAction(editorAction: EditorAction) {
actionsPublisher.accept(action)
}
}
Then, inside our fragment, we were now observing only the single state that was emitted from the ViewModel, and not a bunch of observables as shown inside the MVVM example.
class MainActivity : Fragment() {
fun setupViewModel() {
editorViewModel.state.observe(this, Observer { state ->
render(state)
})
editorViewModel.onAction(EditorAction.LoadProjectAction("384"))
}
private fun render(editorState: EditorState){
if (editorState.loading) {
// show loading
} else if (editorState.error != null) {
// switch to show error
} else {
// render screen normally
}
}
}
This approach that we initially went with had many benefits and advantages over multiple LiveData observables as we saw in the MVVM example earlier. Some of the advantages include:
- We are now avoiding issues with different states being emitted from different
LiveDataobjects that can emit at any time. We have a single state controlling this. - Using the data class
.copy()mechanism to update parts of the state that have changed, helped to not lose data along the way, as you only change parts of the object that need to change. - Our UI layer is minimal now - it only fires actions that have happened and there is not any logic sitting inside the view.
- There is a clearer separation of concerns, Actions, Processors, Reducers controlling the UI state. Nothing external is changing the state. This makes it easier to test and ensure it is doing the correct thing.
- There is also a clear pattern that keeps the code clean and allowed us to separate actions into different files, so we didn’t have all the logic inside the ViewModel file either. (We have over 200 unique actions that can happen on a single screen)
But not everything worked as expected with this MVI setup either! 😩 Although for the most part things seemed to work well on the surface, we started observing strange crashes in production and a few race conditions along the way.
Let’s talk a bit about the issues we faced with this particular MVI approach. (Did we mention, it has been a long journey?😅)
Issues with our MVI implementation
Our MVI implementation improved the situation for us quite considerably (separation of concerns, UI-agnostic code, single emitted state, etc), however, due to how “action processors” were implemented, it introduced one big problem: concurrent state access.
actionsPublisher
.compose(actionProcessors) // compose multiple observables together concurrently
.scan(EditorState(), resultReducers) // setup initial state & reduce
The problem with this approach is that actionProcessors, being Observables, run concurrently and in parallel. This introduces a plethora of issues with state reading, processing and writing.
What we implicitly expected from our MVI implementation was a serialized action processing (when only one action is processed at the same time) and a consistent data model:
Unfortunately, that was not the case - and we learned it the hard way. Our MVI implementation was working more like this:
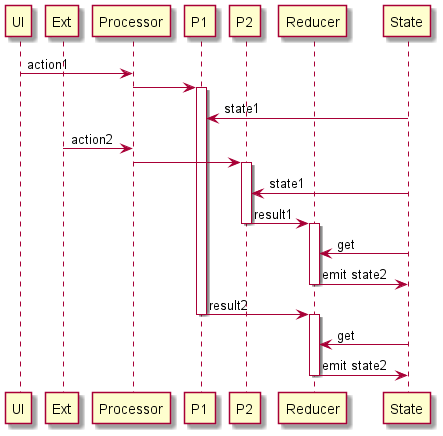
There were multiple reasons why our MVI wasn’t working as expected:
- Lack of synchronization
- Multiple processors were handling events at the same time
- Events were processed asynchronously even within the same processor (due to frequently used
flatMaps) - Results were emitted and processed without any ordering constraints
- Incorrect state access
- Our processors needed to be able to access and modify state to process actions properly. This often resulted in state being read at the beginning of processing and being overwritten at the end of processing - causing a lot of race conditions in case multiple events were processed at the same time.
Our MVI implementation was fine when events were sent sporadically and were processed quickly enough - before new events were sent. However, as we increased the frequency of sending events and increased processing time, all sorts of race conditions and data inconsistencies started to emerge.
Solution 🧪
Having identified all the shortcomings of our current implementation, we came up with a new set of requirements for the new implementation:
- Unidirectional flow of data: actions in, state out - we knew this was a good assumption and wanted to stick with it.
- Concurrency
- Synchronized state access - we couldn’t let multiple concurrent jobs read and write state as they pleased
- Non-blocking events processing - receiving events had to be as fast as possible, however, processing could be much slower (i.e. requiring slow I/O operations, like network calls) and should not block the processing of new events
- Ordering
- First in, first out - events had to be processed in the order they were sent/arrived
- Processing actions one at a time - or, more precisely, actions should read and modify state one at a time
- Testability and reliability
- Unit test coverage
- Encourage usage of immutable state
- … use pure functions
We figured that what we really need was a simple state machine that processes events in a serialized way:
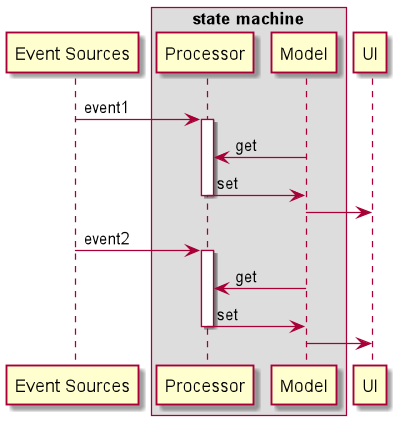
This was ideal for events that could update the state of the model instantly and without access to any external state *(i.e. without doing any long I/O operations like network calls). The tricky part was handling events that needed a lot of processing without blocking the processing of other events. What we ended up doing in such cases was splitting the processing of such events into two: an event that would update the state instantly with appropriate info (i.e. “operation in progress”) and then delegating the processing to a background *effect handler which would, at some point, emit yet another event - an event with the result of the asynchronous operation.
In the end, we settled on a state machine that processes events (input) one by one, updates our model (state) in a synchronous manner and handles any side-effects on a background thread that, if necessary, also sends events into the state machine:
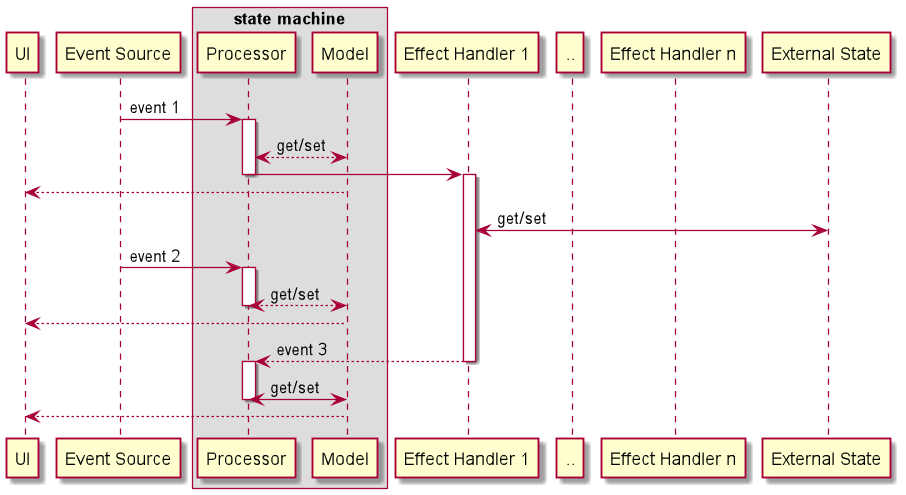
While such architecture did not remove the complexity of handling concurrent operations (those still need to be tracked and handled properly, i.e. started, stopped, ignored if obsolete, etc), it did give us a solid framework with strong assertions around state consistency and available state transitions.
Before we embarked on a journey of implementing everything from scratch, we did a bit of research into available solutions and found this little gem of a framework, Mobius. As it turned out, developers at Spotify faced the same issues and solved them for us already!
Spotify’s Mobius framework
The framework is pretty straightforward to use (we wholeheartedly recommend checking out its wiki) and boils down to defining a few things:
- A State class, i.e.:
data class Model (
val loaded: Boolean
)
- Events, i.e.:
sealed class Events {
data class OpenProject(val id: String) : Events()
data class Result(val project: Project?) : Events()
}
- Effects, i.e. (background/long running operations):
sealed class Effects {
data class LoadProject(val id: String) : Effects()
}
- State transitions, i.e.:
fun update() = Update<Model, Events, Effects> { model, event ->
when (event) {
is Events.OpenProject-> {
loaded = false
// emit LoadProject effect
}
is Events.Result -> {
loaded = event.success
}
}
}
- Effects handlers, for handling background processing i.e.:
fun handleEffect(effect: Effects.LoadProject) : Events {
return try {
// load project / make api calls / etc
Events.Result(project)
} catch {
Events.Result(null)
}
}
After digging through and learning the ins and outs of Mobius, we decided to start adopting the framework slowly throughout our app, chipping away at replacing our homegrown framework. We very quickly saw that there were many advantages to using this framework (besides it solving our most complex concurrency issues):
- It is an open-sourced, maintained, production-ready framework with support for Android and RxJava
- The framework forces you to design business logic with consistent state and well-defined events (we have more than 200 unique events on the editor screen!)
- It makes it much easier to reason about app behaviour when you have this kind of structure in place
- We now have a standardized ViewModel implementation across the app
With every new framework or architecture decision, there is likely never going to be the solution that fits everyone, and adopting something like the Mobius Framework also comes with these disadvantages to adopting:
- It requires quite a bit of boilerplate code to set up. We’ve solved this using shared code templates to generate most of the classes we need.
- New framework for people to learn. Any new engineer needs to spend a bit of time learning about the framework, working through some examples and implementing a feature with it.
Summary 🎉
We’ve learnt a lot over the past couple of years, and I don’t doubt that we won’t learn more in the future.
Right now, we have been successfully using Spotify’s Mobius Framework in our app for the past year and have migrated our largest piece of work - the Canvas Editor to use it too. After switching to Mobius in the Canvas Editor, we observed fewer bugs and race conditions with state were resolved. The level of testing and separation of concerns we’ve achieved using MVI over the years has improved our code quality and eliminated the “god class” activity/view Model that we’ve seen in the past.
We hope this write-up of our journey can help you think a bit more about state management and the potential for race conditions with complicated state.
Have any questions or feedback? Feel free to reach out to Rebecca, Kamil or @GoDaddyOSS!
Careers
Interested in working on interesting state problems like the above? Explore the open roles and apply today!

